Gregory V Santoro

- Data Analyst
- Engineer
- U.S. Army Veteran
LinkedIn Profile
Resume
Exploring World Bank Loans with SQL

Introduction
I wanted to practice SQL commands on a real-world dataset. The World Banks International Development Association (IDA) historical statement of credits and grants dataset provided me the perfect opportunity. By analyzing this dataset with SQL, I can gain insights into the distribution of loans across different countries and sectors.
Key Insights
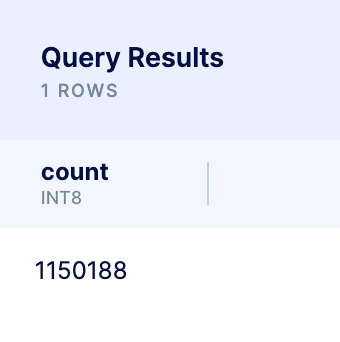
- There’s a total of 1,150,188 transactions present in the dataset
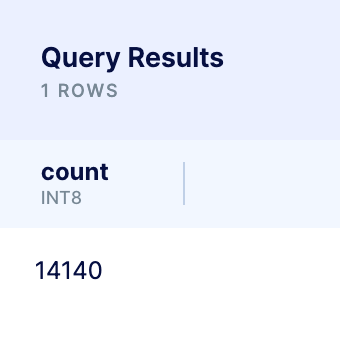
- Of those, 14,140 of those were for the country of Nicaragua
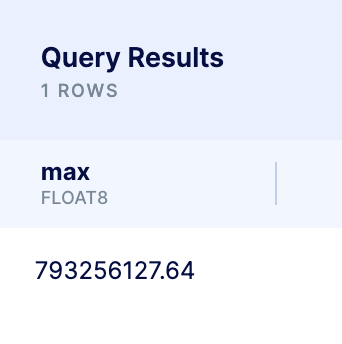
- The largest transaction was $793,256,127.64
- The average interest rate is 0.78%
About The Dataset
The IDA provides concessional loans, grants, and guarantees to its member countries to support their development needs. The data in this dataset is presented in US dollars and calculated using historical exchange rates. You can find the dataset here.
Analysis
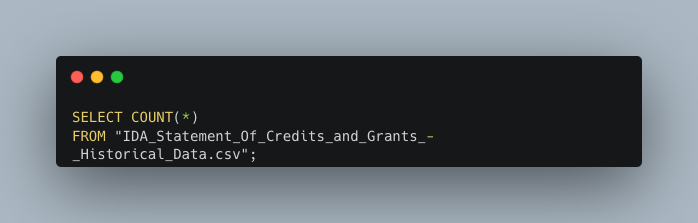
Starting out I want to know how many transactions are present in the dataset. A typical SQL command will start with SELECT. This extracts the data from a database. Following SELECT I’m going to use COUNT(_) and *. COUNT(_) command returns the number of rows that matches the specified criterion within the parantheses. * is a wildcard that represents the names of all the columns in the table.
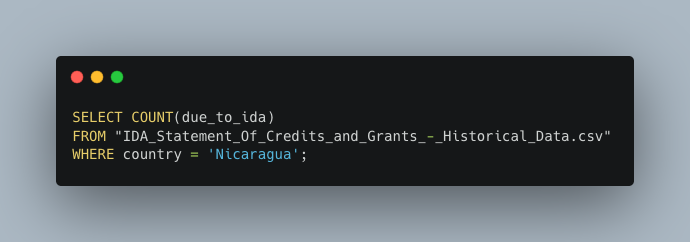
If I wanted to know the breakdown of how many loans each country has, I’d want to include a WHERE clause to be able to filter by a specific criterion. I’ll choose to look at Nicaragua. Instead of COUNT(*), I used the column due_to_ida. If I had used * then we would get the same result. This works because SQL tables are all the same shape, rectangular, meaning all columns have the same number of rows.
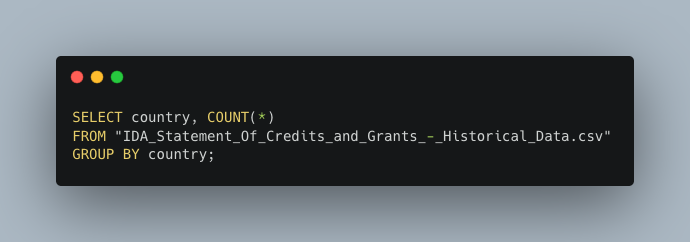
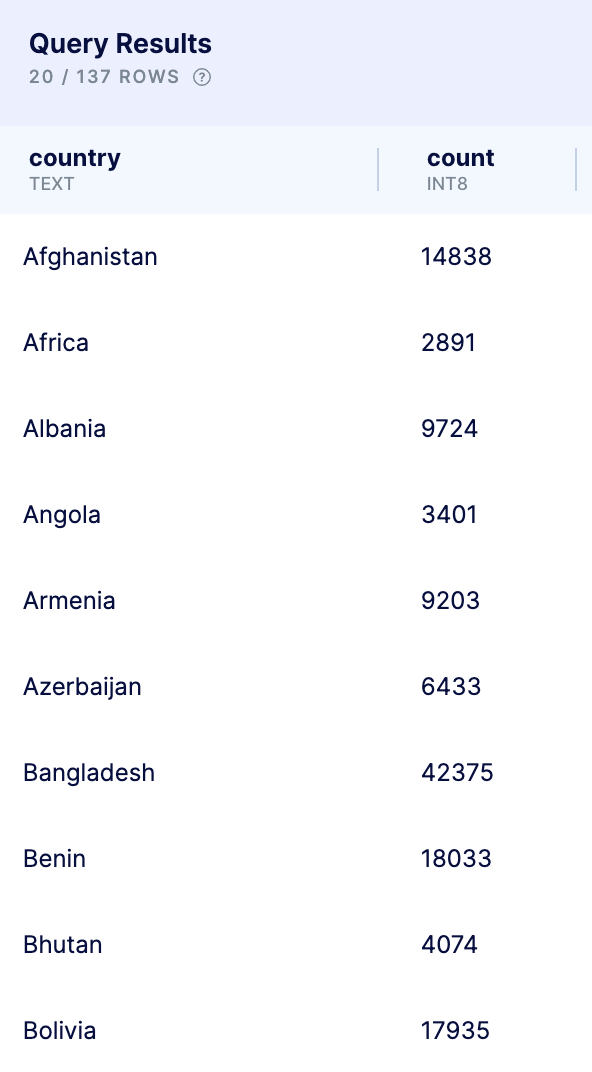
If I wanted to then know the count of loans for all countries, not just Nicaragua, I’d use a GROUP BY statement. It groups rows of the same value to create summary rows.
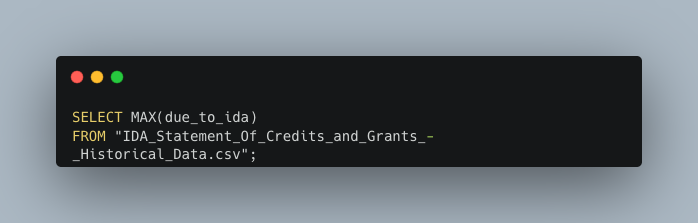
Now let’s say I want to know the largest transaction recorded in the dataset. I’d use the MAX function which if you’re familiar with MS Excel, it simply returns the largest value of a selected range, or in this case, column.
Lastly, I want to know the average interest rate for the loans issued. The dataset defines the column service_charge_rate as the current interest rate or service charge applied to a loan. Using the AVG function takes the average of all the values in that column.

Conclusion
Through my analysis of the IDA dataset using SQL, I was able to gain valuable insights into the count and distribution of loans across different countries and sectors. More analysis can be done later on, but this serves as a nice intro to simpler SQL commands that do wonders to manipulate data and extract useful information quickly from very large datasets.
If you have any feedback or comments for me, please feel free to reach out!